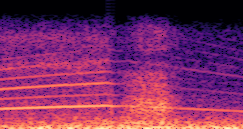
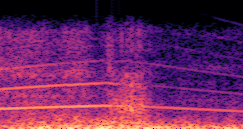
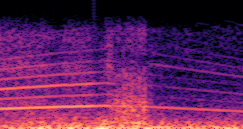
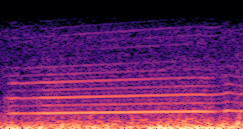
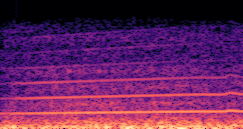
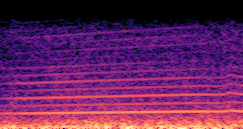
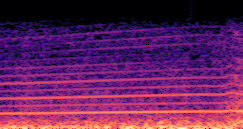
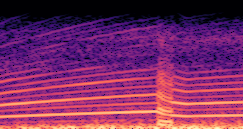
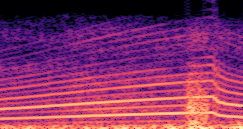
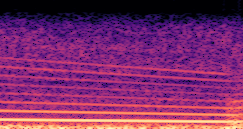
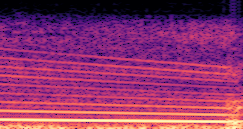
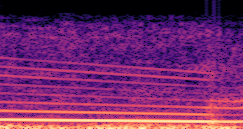
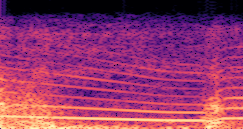
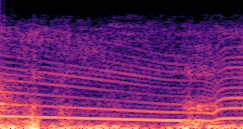
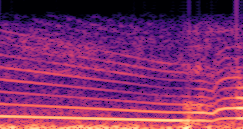
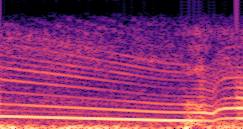
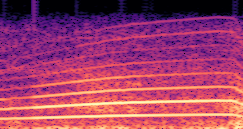
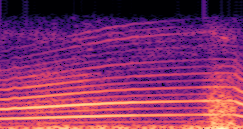
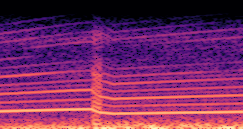
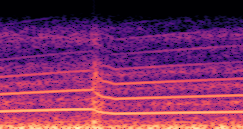
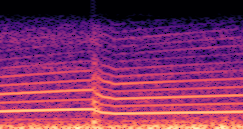
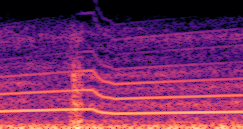
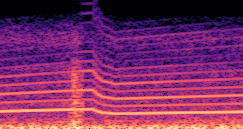
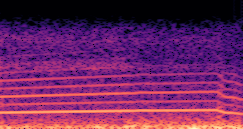
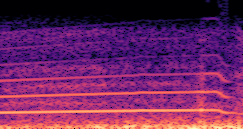
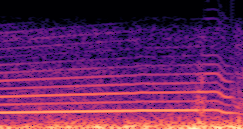
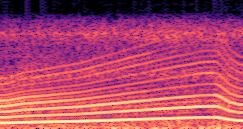
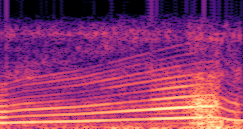
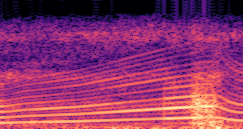
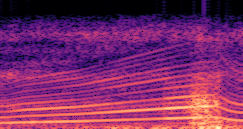
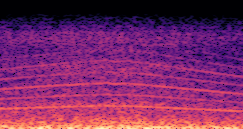
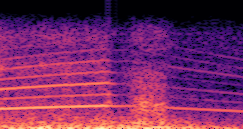
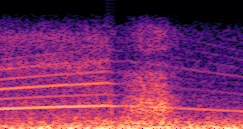
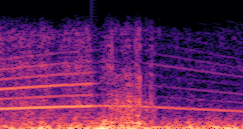
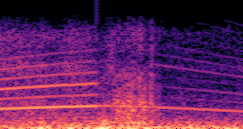
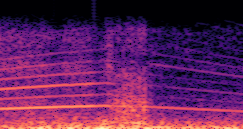
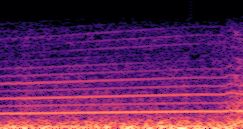
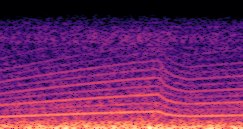
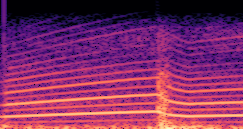
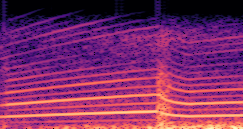
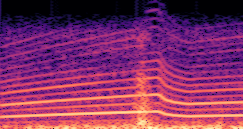
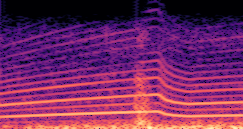
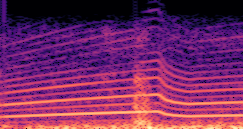
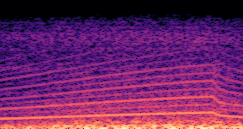
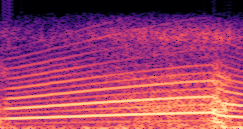
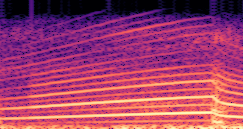
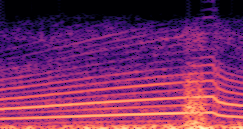
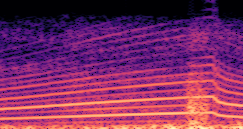
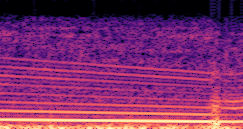
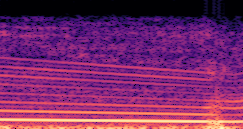
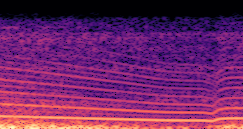
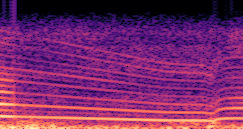
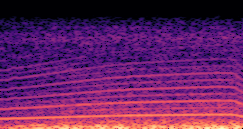
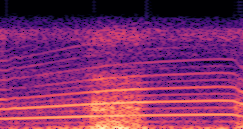
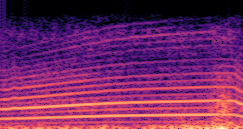
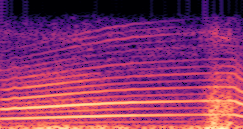
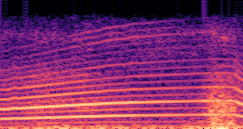
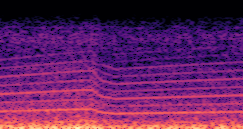
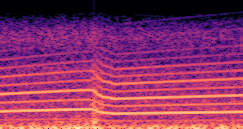
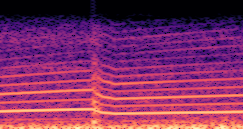
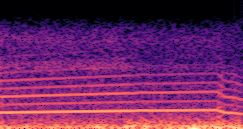
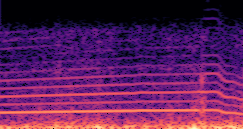
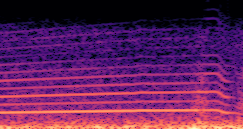
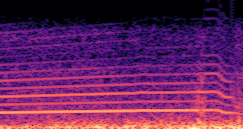
DDSP-Based Neural Vehicle Sound Synthesis from Driving Signals
Minsuk Choi1, Dabin Kim1, Daehun Song2, Juhan Nam1
1 Graduate School of Culture Technology, KAIST, South Korea
2 Hyundai Motor Group, South Korea
Supporting Webpage for the 6th AES International Conference on Automotive Audio, 2026.
Abstract
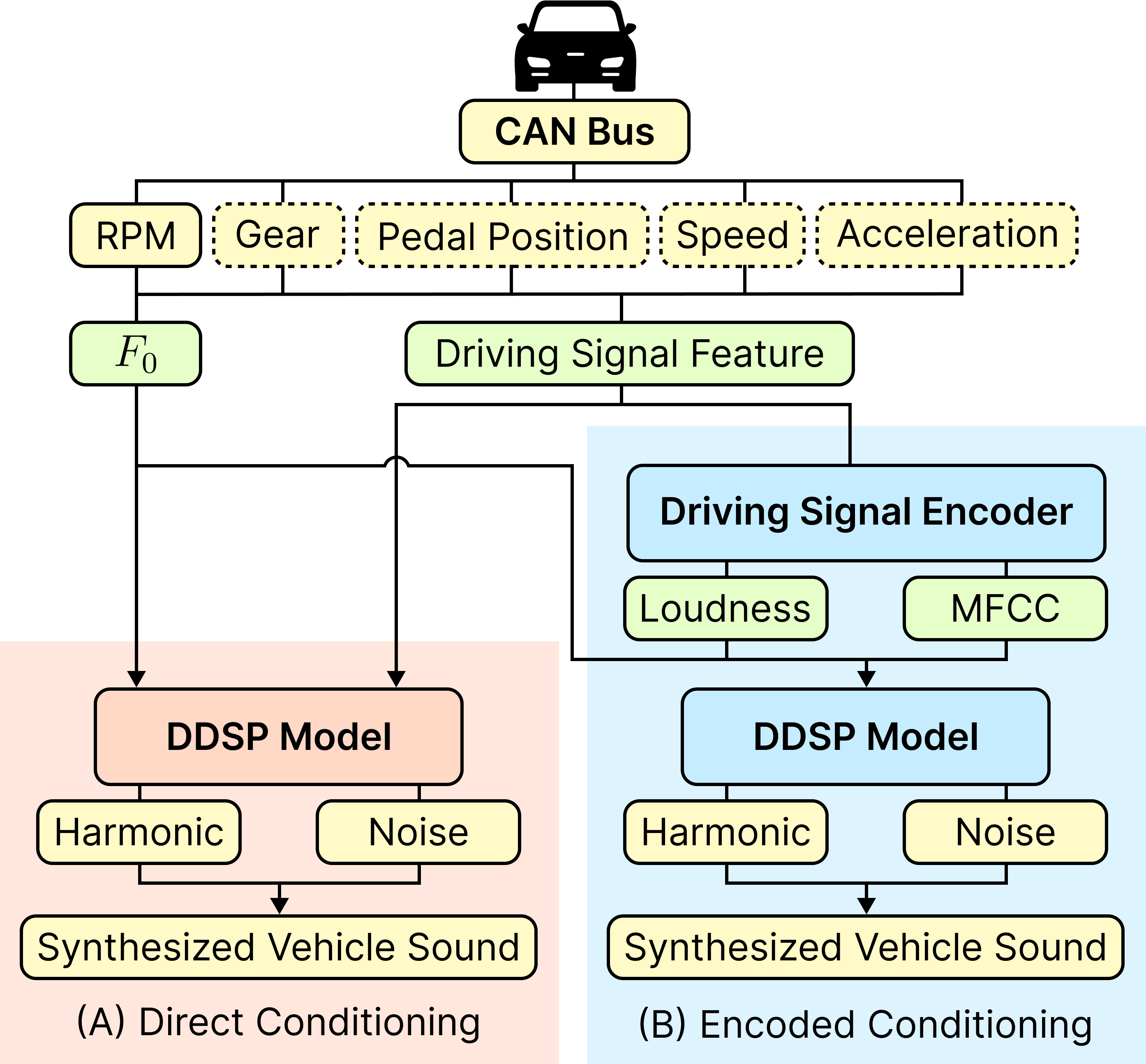
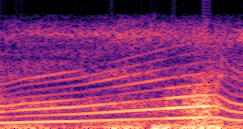
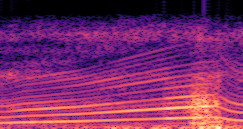
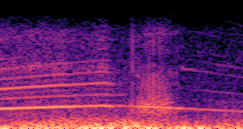
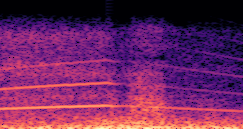
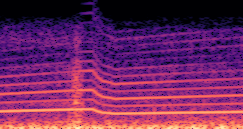
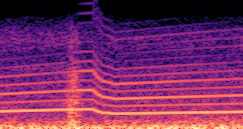
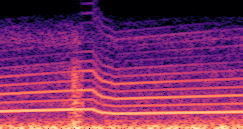
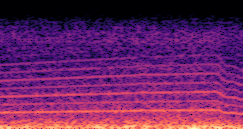
This paper presents a DDSP-based neural vehicle sound synthesis framework conditioned on driving signals collected from the CAN bus of an internal combustion engine (ICE) vehicle, and demonstrates the feasibility of realistic and coherent vehicle sound synthesis within this framework. We investigate three design choices for synthesis configuration: the definition of the fundamental frequency (F0), the configuration of driving signal inputs, and the conditioning representation. Specifically, we compare crank-based and firing-based F0 definitions, multiple driving signal combinations constructed from engine RPM, gear level, accelerator pedal position, vehicle speed, and longitudinal acceleration, and two conditioning representations: direct and encoded conditioning. The framework is evaluated using objective and subjective measures together with qualitative spectrogram observation. The results show that the crank-based F0 provides more accurate synthesis than the firing-based F0 in the present four-cylinder four-stroke vehicle setting. Richer driving signal configurations generally improve synthesis quality, while the contribution of individual signals depends on their redundancy and complementarity. Encoded conditioning yields better objective performance, especially when the available driving signals are limited, whereas direct conditioning achieves the best perceptual results under full driving signal configuration and offers practical advantages in simplicity and efficiency. These findings provide practical guidelines for DDSP-based neural vehicle sound synthesis and highlight the potential of driving-signal-conditioned neural audio synthesis for automotive audio applications such as vehicle sound design and driving simulation.
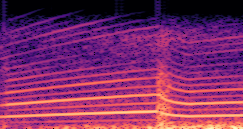
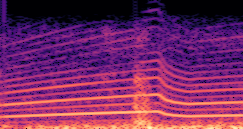
Demo A: F0 Definition
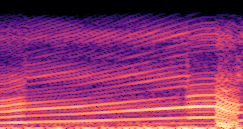
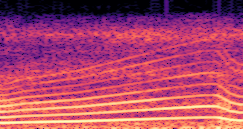
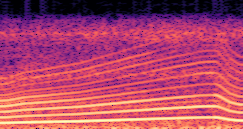
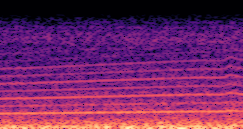
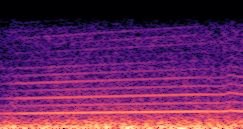
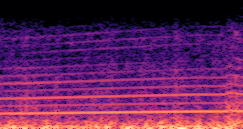
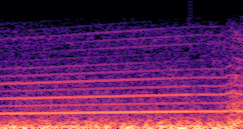
Compares synthesized vehicle sounds using crank-based and firing-based F0 definitions under direct and encoded conditioning.
| Candidate |
Description |
| Ground Truth |
The reference audio. |
Direct
Firing-based |
Synthesized audio using direct conditioning with the firing-based F0 definition. |
Direct
Crank-based |
Synthesized audio using direct conditioning with the crank-based F0 definition. |
Encoded
Firing-based |
Synthesized audio using encoded conditioning with the firing-based F0 definition. |
Encoded
Crank-based |
Synthesized audio using encoded conditioning with the crank-based F0 definition. |
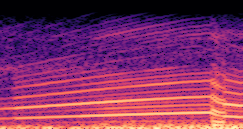
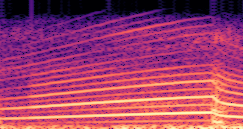
Demo B: Driving Signal Configuration
Compares synthesized vehicle sounds across driving signal configurations: (RPM), (RPM, Gear Level, Pedal Position) and (RPM, Gear Level, Pedal Position, Speed, Acceleration), under direct and encoded conditioning.
| Candidate |
Description |
| Ground Truth |
The reference audio. |
Direct
(RPM) |
Synthesized audio using direct conditioning with (RPM). |
Direct
(RPM, Gear Level, Pedal Position) |
Synthesized audio using direct conditioning with (RPM, Gear Level, Pedal Position). |
Direct
(RPM, Gear Level, Pedal Position, Speed, Acceleration) |
Synthesized audio using direct conditioning with (RPM, Gear Level, Pedal Position, Speed, Acceleration). |
Encoded
(RPM) |
Synthesized audio using encoded conditioning with (RPM). |
Encoded
(RPM, Gear Level, Pedal Position) |
Synthesized audio using encoded conditioning with (RPM, Gear Level, Pedal Position). |
Encoded
(RPM, Gear Level, Pedal Position, Speed, Acceleration) |
Synthesized audio using encoded conditioning with (RPM, Gear Level, Pedal Position, Speed, Acceleration). |